(一)初步认识EVM字节码 (二)状态变量的赋值 (三)函数调用
状态变量的字节码
对于最简单的情况,我们观察它部署时的情况
1 2 3 4 5 6 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract Empty{ uint a; }
EVM 汇编如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ======= Empty.sol:Empty ======= EVM assembly: /* "Empty.sol":69:95 contract Empty{... */ mstore(0x40, 0x80) callvalue dup1 iszero tag_1 jumpi 0x00 dup1 revert tag_1: pop dataSize(sub_0) dup1 dataOffset(sub_0) 0x00 codecopy 0x00 return stop sub_0: assembly { /* "Empty.sol":69:95 contract Empty{... */ mstore(0x40, 0x80) 0x00 dup1 revert auxdata: 0xa2646970667358221220d1d81e685eb83003c8d41cb6d5eccdc8b72a166840e80f7c1683a982795b1dec64736f6c634300080a0033 }
存储布局如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 { "storage" : [ { "astId" : 3 , "contract" : "Empty.sol:Empty" , "label" : "a" , "offset" : 0 , "slot" : "0" , "type" : "t_uint256" } ] , "types" : { "t_uint256" : { "encoding" : "inplace" , "label" : "uint256" , "numberOfBytes" : "32" } } }
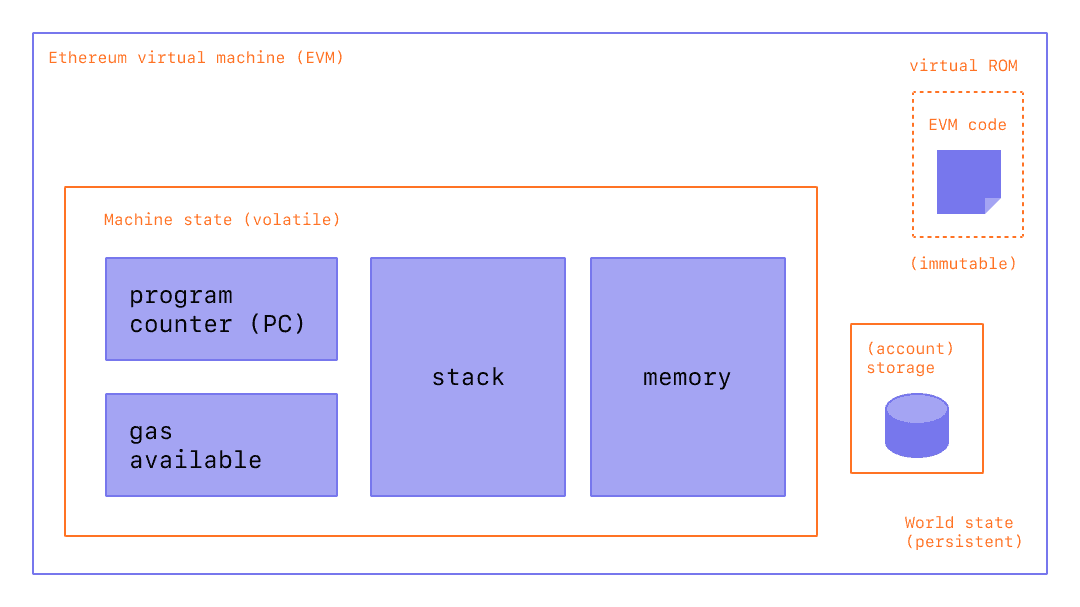
对比前面无状态变量的情况,我们发现指令几乎一致,只有辅助数据 auxdata 有差别。这就引出了一个重要的观点:EVM 只担任执行指令并更改状态的角色,如何操作 (指令) 都是由 solc 决定。对于 EVM 来讲,每个合约账户的 storage 是初始全为 0 的 2^256 个 32 字节的 slot。这并不像内存是按需分配,需要内存扩展。
静态类型
静态类型可以简单的理解为 int uint 之类的常规变量。
普通变量
看简单的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract StaticVariable { uint a;//256位 uint128 b;//占128位 bytes8 c;//占64位 int64 d;//占64位 constructor(){ a=2314; b= 7; c="1011"; d= 15; } }
下面是汇编代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 ======= staticVariable.sol:StaticVariable ======= EVM assembly: /* "staticVariable.sol":70:270 contract StaticVariable {... */ mstore(0x40, 0x80) /* "staticVariable.sol":185:268 constructor(){... */ callvalue dup1 iszero tag_1 jumpi 0x00 dup1 revert tag_1: pop /* "staticVariable.sol":210:214 2314 */ 0x090a /* "staticVariable.sol":208:209 a */ 0x00 /* "staticVariable.sol":208:214 a=2314 */ dup2 swap1 sstore pop /* "staticVariable.sol":227:228 7 */ 0x07 /* "staticVariable.sol":224:225 b */ 0x01 0x00 /* "staticVariable.sol":224:228 b= 7 */ 0x0100 exp dup2 sload dup2 0xffffffffffffffffffffffffffffffff mul not and swap1 dup4 0xffffffffffffffffffffffffffffffff and mul or swap1 sstore pop /* "staticVariable.sol":238:246 c="1011" */ 0x3130313100000000000000000000000000000000000000000000000000000000 /* "staticVariable.sol":238:239 c */ 0x01 0x10 /* "staticVariable.sol":238:246 c="1011" */ 0x0100 exp dup2 sload dup2 0xffffffffffffffff mul not and swap1 dup4 0xc0 shr mul or swap1 sstore pop /* "staticVariable.sol":259:261 15 */ 0x0f /* "staticVariable.sol":256:257 d */ 0x01 0x18 /* "staticVariable.sol":256:261 d= 15 */ 0x0100 exp dup2 sload dup2 0xffffffffffffffff mul not and swap1 dup4 0x07 signextend 0xffffffffffffffff and mul or swap1 sstore pop /* "staticVariable.sol":70:270 contract StaticVariable {... */ dataSize(sub_0) dup1 dataOffset(sub_0) 0x00 codecopy 0x00 return stop sub_0: assembly { /* "staticVariable.sol":70:270 contract StaticVariable {... */ mstore(0x40, 0x80) 0x00 dup1 revert auxdata: 0xa26469706673582212207eb20293ec4fc5cc1b2fe0cc5fc4691d8c1b048202104c5ca6afa58f9012116f64736f6c634300080a0033 }
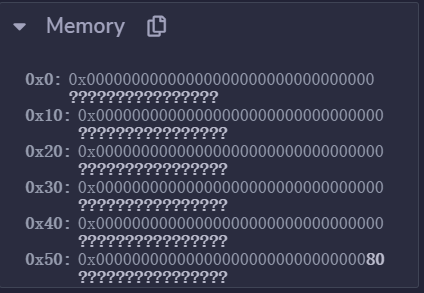
关键看 tag1 中初始化的过程。sstore 的时候栈如下
[ “0x0000000000000000000000000000000000000000000000000000000000000000”, “0x000000000000000000000000000000000000000000000000000000000000090a”, “0x000000000000000000000000000000000000000000000000000000000000090a” ]
发现将在 00 的位置给 a 赋值 0x90a,这是非常直接的操作,建议读者单步调试观察。
1 2 3 4 5 1. 数值压栈 2. 存储位置压栈 3. 复制数值到栈顶 4. 将栈顶数值与存储位置互换 5. sstore
但是由于 b 不够 256 位,不能占满一个 slot,因此就需要进行相对复杂的位操作。
PUSH1 07,数值压栈。
PUSH1 01, PUSH1 00, PUSH2 0100, EXP,01 是 slot 的序号,0 表示移位几个字节,因为这是 slot 1 的第一个变量,所以为 0。0x0100 表示一个字节,与随后的操作码 EXP,计算指数,得到最终的偏移量。
DUP2, SLOAD 复制 slot 的序号,取出里面的内容。
DUP2, PUSH16 ffffffffffffffffffffffffffffffff, MUL, NOT 复制偏移量,然后与掩码相乘,然后取反得到最终的掩码。
AND slot 1 的序列和掩码取与,得到左半部分 128 位的内容。
SWAP1, DUP4, PUSH16 ffffffffffffffffffffffffffffffff, AND, MUL 将偏移量置于栈顶,然后将赋值的数据复制到栈顶,接着和掩码按位取与,最后乘上偏移量,实现了右边 128 位的赋值。
OR 与左边 128 位按位取或,实现了对 slot 1 的处理。
SWAP1, SSTORE 将 slot 序号交换到栈顶,写入 slot 1.
具体过程请见附录 II a .
对于变量 c,注意到它是在 slot1,偏移 16 个字节。参考 solidity doc 可以知道 bytes 默认是使用 ASCII 编码存储的,0 表示为 0x30, 1 表示为 0x31 因此 1011 在存储中表示为 0x3130313100000000.
PUSH 3130313100000000000000000000000000000000000000000000000000000000,说明对于 bytes1 到 bytes32 都是直接先从高位开始传入字符。PUSH1 01 PUSH1 10 PUSH2 0100 EXP,01 用于后续加载 slot1 的内容。然后偏移量为 0x10 字节。后面和上一个变量类似,掩码操作,取出对应位置的 8 个字节。
将 3130313100000000000000000000000000000000000000000000000000000000 右移 oxc0 位,也就是 24 个字节,这样就恰好是我们需要的 8 个字节。
将我们需要的 8 个字节按照它存储的布局,依靠第 2 步确定的偏移量,偏移 0x10 字节。
OR 之后 SSTORE 存储。
变量 d 的操作很类似,值得一提的是 SIGNEXTEND 这个操作码。符号扩展有两个参数,第一个参数是数值的字节数减一,第二个参数是栈内数值。这样说可能有些模糊,读者可以阅读它的操作码说明 。
最后的存储布局如下,故意加空格是为了突出不同的变量。可以看到变量的存储是从左边开始的。
1 2 3 4 5 6 7 8 9 key: 0x0000000000000000000000000000000000000000000000000000000000000000 value: 0x000000000000000000000000000000000000000000000000000000000000090a key: 0x0000000000000000000000000000000000000000000000000000000000000001 value: 0x000000000000000f 3130313100000000 00000000000000000000000000000007
最后,观察逆向后的伪代码会更加清晰。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } storage[0x00] = 0x090a; storage[0x01] = (storage[0x01] & ~0xffffffffffffffffffffffffffffffff) | (0xffffffffffffffffffffffffffffffff & 0x07); storage[0x01] = (storage[0x01] & ~(0xffffffffffffffff * 0x0100 ** 0x10)) | (0x3130313100000000000000000000000000000000000000000000000000000000 >> 0xc0) * 0x0100 ** 0x10; storage[0x01] = (storage[0x01] & ~(0xffffffffffffffff * 0x0100 ** 0x18)) | (0xffffffffffffffff & signextend(0x07, 0x0f)) * 0x0100 ** 0x18; memory[0x00:0x3f] = code[0xd0:0x010f]; return memory[0x00:0x3f]; } }
结构体
结构体在汇编的视角,只是语法糖,相当于里面的变量「拆开」排布,区别在于结构体开始存储的 slot 和最后结束存储的 slot 都不能和其他变量共享。
可以观察下面的这个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 // SPDX-License-Identifier: GPL-3.0 pragma solidity 0.8.10; contract StructTest1 { struct Member { address userAddr;//20字节 uint balance;//32字节 bool vip;//1字节 } Member customer; constructor(){ customer.userAddr=msg.sender; customer.balance = 100; customer.vip=false; } }
从下面的逆向代码,也可以看出来上面提到的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } storage[0x00] = msg.sender | (storage[0x00] & ~0xffffffffffffffffffffffffffffffffffffffff); storage[0x01] = 0x64; storage[0x02] = (storage[0x02] & ~0xff) | 0x00; memory[0x00:0x3f] = code[0x88:0xc7]; return memory[0x00:0x3f]; } }
数组
元素赋值
1 2 3 4 5 6 7 8 9 10 11 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract Array { uint[9] a; constructor(){ a[0]=1; } }
这是最简单的例子,下面是逆向后的伪代码。var0 保存需要赋予的值,然后 var1 是数组开始的 slot 的位置,var2 是数组的索引,0x09 是数组长度。然后由于 uint 类型刚好占满 256 位,所以寻址比较简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var0 = 0x01; var var1 = 0x00; var var2 = var1; if (var2 < 0x09) { storage[var2 + var1] = var0; memory[0x00:0x3f] = code[0x68:0xa7]; return memory[0x00:0x3f]; } else { var var3 = 0x22; memory[0x00:0x20] = 0x4e487b7100000000000000000000000000000000000000000000000000000000; memory[0x04:0x24] = 0x32; revert(memory[0x00:0x24]); } } }
看复杂一点儿的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract Array { uint[9] a; constructor(){ a[0]=1; a[1]=2; a[6]=1234; } }
逆向伪代码如下,我直接在下面用注释解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var0 = 0x01;//将赋值1 var var1 = 0x00;//数组从slot0开始 var var2 = var1;//数组的索引 if (var2 < 0x09) {//一般都会符合这个,因为编译器会检查 storage[var2 + var1] = var0;//赋值a[0]=1 var0 = 0x02;//以下内容完全类似 var1 = 0x00; var2 = 0x01; if (var2 < 0x09) { storage[var2 + var1] = var0; var0 = 0x04d2; var1 = 0x00; var2 = 0x06;//注意数组索引变成6 if (var2 < 0x09) { storage[var2 + var1] = var0; memory[0x00:0x3f] = code[0x9b:0xda]; return memory[0x00:0x3f]; } else { var var3 = 0x55; label_005F: memory[0x00:0x20] = 0x4e487b7100000000000000000000000000000000000000000000000000000000; memory[0x04:0x24] = 0x32; revert(memory[0x00:0x24]); } } else { var3 = 0x3b; goto label_005F; } } else { var3 = 0x22; goto label_005F; } } }
字面量赋值
我们继续观察字面量的赋值特征:
1 2 3 4 5 6 7 8 9 10 11 12 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract Array { uint[9] a; constructor(){ a=[1,2,3,4,5]; } }
字面量的处理实际上较为复杂,我们慢慢分析,依然主要看注释。下面先补充一些分析:
字面量所需的空间在编译时是不确定的,因此赋值时必然需要内存辅助,则会涉及到内存指针(分配的内存大小)、内存拓展。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var temp0 = memory[0x40:0x60]; memory[0x40:0x60] = temp0 + 0xa0;//内存拓展 0xa0 字节 memory[temp0:temp0 + 0x20] = 0xff & 0x01;//0x20字节连续存放数组的字面量,通过掩码取值。虽然这里掩码看上去是多余的,但是对于复杂情况则很有用。 var temp1 = temp0 + 0x20; memory[temp1:temp1 + 0x20] = 0xff & 0x02; var temp2 = temp1 + 0x20; memory[temp2:temp2 + 0x20] = 0xff & 0x03; var temp3 = temp2 + 0x20; memory[temp3:temp3 + 0x20] = 0xff & 0x04; memory[temp3 + 0x20:temp3 + 0x20 + 0x20] = 0xff & 0x05; var0 = 0x59; var var1 = 0x00;//数组开始的slot位置 var var2 = temp0;//内存中开始写入数据的位置 var var3 = 0x05;//字面量的元素个数 var0 = func_005E(var1, var2, var3);//(数组开始slot位置,内存开始位置,元素个数)开始把内存中的值写入存储 memory[0x00:0x3f] = code[0xc7:0x0106]; return memory[0x00:0x3f]; } function func_005E(var arg0, var arg1, var arg2) returns (var r0) { var var0 = arg0;//0x00 var temp0 = arg1;//0x80 arg1 = var0 + 0x09;//数组结束slot位置 var var1 = temp0;//0x80 if (!arg2) {//需要写入的元素个数为0,即字面量为空,我们不讨论异常情况 label_008F://这是结束的语句块, var temp1 = arg1; arg1 = 0x9a; var0 = var0;//数组开始的slot位置 arg2 = temp1;//数组结束的slot位置 arg1 = func_009E(arg2, var0); return arg0; } else { var temp2 = arg2;//元素个数 var temp3 = var1;//0x80内存开始位置 arg2 = temp3;//内存开始位置 var1 = arg2 + temp2 * 0x20;//计算内存结束位置 if (var1 <= arg2) {//这是为了防止溢出,编译器的异常处理 label_008E: goto label_008F; } else {//下面是正常情况 label_0078: var temp4 = arg2;//内存开始位置 var temp5 = var0;//数据存储起始位置 storage[temp5] = memory[temp4:temp4 + 0x20] & 0xff; arg2 = temp4 + 0x20;//内存开始位置向后32字节 var0 = temp5 + 0x01;//存储中的数组索引+1 var1 = var1; if (var1 <= arg2) { goto label_008E; }//内存读取位置到达结束位置,跳转到结束的语句块 else { goto label_0078; }//重复执行,直到所有的值都写入了 } } } function func_009E(var arg0, var arg1) returns (var r0) {//(结束的存储位置,开始存储位置) if (arg0 <= arg1) {//通过递增,开始位置已经到达结束位置,可以结束 label_00B5: return arg0; } else { label_00A7: var temp0 = arg1; storage[temp0] = 0x00;//这里可能是为了回滚,需要把数据置为默认值 arg1 = temp0 + 0x01; if (arg0 <= arg1) { goto label_00B5; }//结束 else { goto label_00A7; }//如果还没结束就自增 } } }
变量需要 compact 的情况
关于 compact 是什么,请见 Layout of State Variables in Storage ,这里不赘述,而且本文默认读者已经有这些基础。
首先,我们可以猜想,它和上面恰好占满 slot 的情况的差别在于,它需要使用掩码取数,而且 int24 类型的赋值需要符号扩展。
1 2 3 4 5 6 7 8 9 10 11 12 13 // SPDX-License-Identifier: GPL-3.0 pragma solidity 0.8.10; contract Array { int24[9] a; constructor(){ a[3]=11; a=[int24(1),2,3,4,5]; } }
我们仍然观察逆向后的伪代码,它比字节码多了一层抽象,适合初学者分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 contract Contract { function main() { memory[0x40:0x60] = 0x80;//初始内存数据开始位置 var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var0 = 0x0b;//赋值的数11 var var1 = 0x00;//数组开始的slot var var2 = 0x03;//索引为3 if (var2 < 0x09) { var temp0 = var2;//复制索引 var temp1 = temp0 / 0x0a + var1;//计算 slot 位置,一个 slot 最多容纳 0x0a 个元素 var temp2 = 0x0100 ** (temp0 % 0x0a * 0x03);//temp0 % 0x0a表示这个slot容纳的元素个数,0x03表示一个元素的字节数,这样计算出了偏移量 storage[temp1] = (signextend(0x02, var0) & 0xffffff) * temp2 | (~(temp2 * 0xffffff) & storage[temp1]);//对赋值的数 2 进行符号扩展,然后通过掩码取数,再根据temp2移位,接着异或,保存slot原来的内容。具体来说,原来slot会通过移位后的掩码,将需要更新的部分置为0。 var temp3 = memory[0x40:0x60];//获取分配的内存大小 memory[0x40:0x60] = temp3 + 0xa0;//内存拓展0xa0字节 //下面可以发现,memory 是不会进行 compact 的,虽然每个元素占用3个字节,但是实际上内存中分配是32字节 memory[temp3:temp3 + 0x20] = signextend(0x02, signextend(0x02, 0x01));//这里符号扩展两次,实际上是因为源码中为了确定数组字面量的类型,进行了强制类型转化,需要符号扩展,然后赋值之前也自动符号扩展。 var temp4 = temp3 + 0x20; memory[temp4:temp4 + 0x20] = signextend(0x02, 0x02); var temp5 = temp4 + 0x20; memory[temp5:temp5 + 0x20] = signextend(0x02, 0x03); var temp6 = temp5 + 0x20; memory[temp6:temp6 + 0x20] = signextend(0x02, 0x04); memory[temp6 + 0x20:temp6 + 0x20 + 0x20] = signextend(0x02, 0x05); //现在准备将内存中的数据写入存储 var0 = 0x009f;//这个辅助的数据没有用到,可能是默认值。 var1 = 0x00; var var3 = 0x05; var2 = temp3; var0 = func_00A5(var1, var2, var3);//(初始slot位置,数组内存开始位置,需要赋值的元素个数) memory[0x00:0x3f] = code[0x01a1:0x01e0]; return memory[0x00:0x3f]; } else { var3 = 0x0027; memory[0x00:0x20] = 0x4e487b7100000000000000000000000000000000000000000000000000000000; memory[0x04:0x24] = 0x32; revert(memory[0x00:0x24]); } } function func_00A5(var arg0, var arg1, var arg2) returns (var r0) { //和之前的类似,计算写入位置 var var0 = arg0;//数组开始slot位置 var temp0 = arg1; arg1 = var0 + (0x09 + 0x09) / 0x0a;//一个slot最多0xa个int24变量。1 var var1 = temp0; if (!arg2) {//需要赋值的元素个数为0,这是异常情况 label_0136: var temp1 = arg1;//1 arg1 = 0x0143; var0 = var0;//0 arg2 = temp1;//1 arg1 = func_0147(arg2, var0); return arg0; } else { var temp2 = arg2;//5 var temp3 = var1;//内存开始位置 arg2 = temp3; var1 = arg2 + temp2 * 0x20;//计算内存结束位置 var var2 = 0x00;//slot内的偏移字节数 if (var1 <= arg2) {//内存结束位置小于内存开始位置,异常处理,可能与回滚有关,笔者暂时不熟悉 label_0105: if (!var2) { goto label_0136; }//赋值结束时执行 var temp4 = var0;//数组存储开始位置 var temp5 = var2;//偏移量 storage[temp4] = ~(0x0100 ** temp5 * 0xffffff) & storage[temp4];//取出第一个元素 var temp6 = temp5 + 0x03;//偏移量增加 3 字节 var temp7 = (temp6 + 0x02) / 0x20;//判断slot位置增量。因为int24之多占满30个字节,slot里有两个字节是闲置且无法使用的。 var0 = temp7 + temp4;//重新计算数组下一次赋值的slot的位置 var2 = 0x01 - temp7 * temp6;//注意,slot的位置必然小于1,因为1是我们传入的数组结束的位置。 goto label_0105; } else { label_00C9: var temp8 = arg2;//内存开始位置 var temp9 = var0;//数组开始的slot位置 var temp10 = var2;//slot内的偏移字节数 var temp11 = 0x0100 ** temp10;//偏移量 storage[temp9] = (signextend(0x02, memory[temp8:temp8 + 0x20]) & 0xffffff) * temp11 | (~(temp11 * 0xffffff) & storage[temp9]);//内存中的值符号扩展后移位,实现复制 arg2 = temp8 + 0x20;//内存偏移量增加32字节 var temp12 = temp10 + 0x03;//slot偏移量增加3字节 var temp13 = (temp12 + 0x02) / 0x20;//重新计算下一个需要赋值的元素的slot位置增量 var0 = temp13 + temp9;//下一个需要赋值的元素的slot位置 var2 = 0x01 - temp13 * temp12;//判断结束时相关 if (var1 <= arg2) { goto label_0105; }//根据内存读取位置判断是否结束赋值 else { goto label_00C9; } } } } function func_0147(var arg0, var arg1) returns (var r0) { if (arg0 <= arg1) {//结束的slot位置小于等于开始的slot位置 label_0160: return arg0; } else { label_0151: var temp0 = arg1;//开始的slot位置 storage[temp0] = 0x00; arg1 = temp0 + 0x01;//开始的slot位置递增 if (arg0 <= arg1) { goto label_0160; } else { goto label_0151; } } } }
读者阅读以上内容时,可能会感觉比较困难。实际上,笔者部分内容也没有弄的很清楚,例如逆向后的代码有许多异常处理、回滚、甚至 try/catch 的逻辑,这些都需要后面慢慢积累。
下面是 JEB 的逆向结果,可见抽象程度更高,通过 JUMPI 判断循环做的很好,但是粒度不够细,类型推断很武断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 contract DecompiledContract { unsigned char[3] g0_9; function start() { uint256 v0, v1; *0x40 = 0x80; if(msg.value != 0x0) { revert(0x0, 0x0); } v3 = storage[0x0]; v0 = signextend(0x2, 0xB); g0_9 = v0 & 0xffffff; uint256 v2 = *0x40; *0x40 = v2 + 0xA0; v1 = signextend(0x2, 0x1); v1 = signextend(0x2, v1); *(uint256*)v2 = v1; v1 = signextend(0x2, 0x2); *(int256*)(v2 + 0x20) = v1; v1 = signextend(0x2, 0x3); *(int256*)(v2 + 0x40) = v1; v1 = signextend(0x2, 0x4); *(int256*)(v2 + 0x60) = v1; v1 = signextend(0x2, 0x5); *(int256*)(v2 + 0x80) = v1; sub_A5(0x5, v2, 0x0);//(赋值的元素个数、内存开始位置、slot的位置) codecopy(0x0, 0x1A1, 0x3F); return(0x0, 0x3F); } function sub_A5(uint256 param0, uint256 param1, uint256 param2) private returns (uint256) { uint256 v0, v1, v2, v3 = param0, v4 = param1; param1 = v3 + 0x1; if(param2 != 0x0) { uint256 v5 = v4; v4 = param2; param2 = v5; v4 = v4 * 0x20 + param2; uint256 i; for(i = 0x0; param2 < v4; i *= 0x1 - (i + 0x2) / 0x20) { v0 = storage[v3]; v1 = signextend(0x2, *(uint256*)param2); storage[v3] = ((v1 & 0xffffff) * 0x100 ** i) | (~(0x100 ** i * 0xffffff) & v0); param2 += 0x20; i += 0x3; v3 += (i + 0x2) / 0x20; } while(i != 0x0) { v2 = storage[v3]; storage[v3] = ~(0x100 ** i * 0xffffff) & v2; i += 0x3; v3 += (i + 0x2) / 0x20; i *= 0x1 - (i + 0x2) / 0x20; } } sub_147(v3, param1); return param0; } function sub_147(uint256 param0, uint256 param1) private returns (uint256) { while(param0 > param1) { storage[param1] = 0x0; ++param1; } return param0; } }
可以发现在 label_00C9 实际赋值的后面,var2 = 0x01 - temp13 * temp12; 语义比较奇怪,为什么是 [结束位置的slot]-[slot增量]*[偏移量] 呢?我们通过控制变量的办法进行对比分析。首先,我猜想是结束的位置的判断,改变结束的 slot 的位置。
因此可以得到初步结论,var2 = 0x01 - temp12 * temp11 是用于异常处理,和 int24 类型相关,用于跨 slot 时设置新的偏移量。也可能是用于清理某些垃圾数据,这和编译器的设计,漏洞处理相关,因此不深入探讨。
字节码和逆向小结
直接分析字节码是相当困难的,因为人脑需要抽象,足够的抽象层次才能有效地进行逻辑分析。
借助辅助工具,如 Remix IDE 单步调试、逆向工具,可以辅助分析。尤其是逆向工具,可以简化一步一步跟踪堆栈的工作,直接关注计算、比较、赋值、跳转等核心逻辑。
JEB 逆向工具虽然抽象程度更高,但是准确度较低。而更细粒度的在线的逆向工具,可能更适合一些。
异常处理也是比较困难的部分,需要大量的经验和编译器基础,才会较为轻松。
字节码相关的博客较少,因为太过于深入、理论,往往需要查阅相关论文。
读者可以通过前面的深入探究的过程,总结学习的方法。
动态类型
动态类型是值不定长的类型,例如 bytes, int[] 等等,我们通过简单的例子来说明。
bytes
1 2 3 4 5 6 7 8 9 10 11 12 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract SimpleDynamicVariable { bytes a; constructor(){ a="abc"; } }
首先观察操作码,可以得到如下分析。
注意内存是按照字节编址,大端序 。例如每一行是从右往左数,0x0 这一行左边的 00 是第 10 个字节。
它主要用于存储数组等较大的临时存储的数据。最开始默认的内存是 0x80 字节,因为之前的空间有特殊的用途,然后拓展了 0x40 字节,内存指针位置这是给 bytes 预分配的内存,作者猜测这是 bytes 默认的初次拓展的内存大小,后文会继续深入。
abc 字符串按照 ASCII 编码,然后存入内存中。之所以存入内存,是因为 bytes 类型可能占用超过 32 字节,无法一次性通过栈操作。值得提出来的是,Remix IDE 内存视图中许多的问号,表示无法通过 ASCII 可视字符表示的值。这样能够直观的看到内存的内容。
变量 a 实际上相当于含有 3 个元素的 byte1[] 类型,因此在第 29 步中 PUSH1 03,这样得到动态数组数据存储的位置。在某些地方通过哈希值寻找存储位置的方式,会叫做哈希指针 ,但是这和一般意义的指针是完全不一样的。
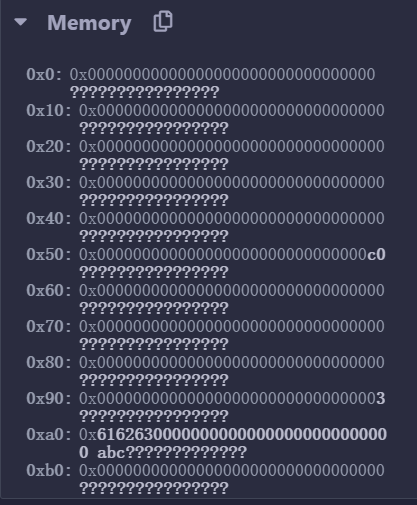
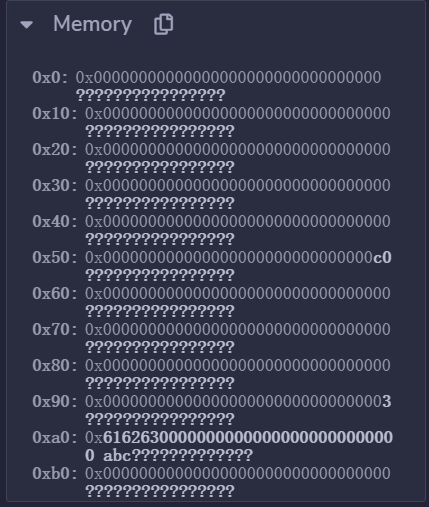
设置内存偏移为0x80+0x20,因为 bytes 长度用 32 字节存储。这里长度为 3,0xa0 后暂时存储 byets 的数据 6162630000000000000000000000000000000000000000000000000000000000
我们再次回顾内存布局,0x0-0x3f 是哈希函数的暂存空间,0x40-0x5f 表示分配的内存大小,0x60-0x80 是动态数组的默认值,0x80-0x9f 是字节数组 a 的长度,0xa0-0xbf 是字节数组 a 的值。
内存偏移量为 0x80,载入 32 字节的数组长度到栈顶,将要计算哈希。
由于操作码太多了,我们直接分析下面逆向后的伪代码。
需要注意:如果 bytes 数据不超过 31 字节,那么在变量所在的 slot 中,高 31 字节用于存放数据,最低的字节存放 数组占用字节长度*2。如果数据超过 31 字节,那么数据和变量要分开存储,变量所在的 slot 存放 数组占用字节长度*2+1,数据存放在序号为 keecak(变量所在slot序号) 的 slot 中。string 也满足这样的规律。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var temp0 = memory[0x40:0x60]; memory[0x40:0x60] = temp0 + 0x40;//内存拓展40个字节 memory[temp0:temp0 + 0x20] = 0x03;//元素个数 memory[temp0 + 0x20:temp0 + 0x20 + 0x20] = 0x6162630000000000000000000000000000000000000000000000000000000000;//61 62 63 对应着 abc 的ASCII编码,而且bytes本质上是bytes1的数组 var0 = 0x005c; var var1 = 0x00;//数组开始的slot位置 var var3 = memory[temp0:temp0 + 0x20];//取出元素个数 var var2 = temp0 + 0x20;//内存中数组开始的位置 var0 = func_0062(var1, var2, var3); memory[0x00:0x3f] = code[0x0174:0x01b3]; return memory[0x00:0x3f]; } function func_0062(var arg0, var arg1, var arg2) returns (var r0) {//(slot起始位置,内存起始位置,元素个数) var var0 = arg0; var var1 = 0x006e;//默认的byte的元素个数为0x6e var var2 = storage[var0];//取出slot中的数, var1 = func_0134(var2);//返回原来这个slot中的元素个数 memory[0x00:0x20] = var0;//需要哈希的数据,这里是slot的位置 .0 var0 = keccak256(memory[0x00:0x20]);//哈希后的数据位置 var temp0 = var0 + (var1 + 0x1f) / 0x20;//计算结束的slot位置 var1 = arg1;//内存起始位置 arg1 = temp0;//结束的slot位置 if (!arg2) {//元素个数为0,那么默认空值 storage[arg0] = 0x00; goto label_00D7; } else if (0x1f < arg2) {//元素个数不为0,但是多于0x1f个,也就是说一个slot装不下 var temp1 = arg2; storage[arg0] = temp1 + temp1 + 0x01;//slot存储 2*length+1,因为数组元素8位,所以数组占用的字节长度就是数组长度 if (!temp1) {//数组长度为0 label_00D7: var temp2 = arg1;//结束的slot位置 arg1 = 0x00e4; var0 = var0;//数组数据开始的slot序号 arg2 = temp2;//结束的slot序号 arg1 = func_00E8(arg2, var0);//(结束的slot序号,数组数据开始的slot序号),这里应该是为了回滚,或者说是重置为默认值delete return arg0; } else { var temp3 = arg2;//需要赋值的元素个数 var temp4 = var1;//内存开始位置 arg2 = temp4;//内存开始位置 var1 = arg2 + temp3;//内存结束位置,因为元素个数也等于字节长度 if (var1 <= arg2) {// label_00D6: goto label_00D7; } else { label_00C4: var temp5 = arg2;//内存开始位置 var temp6 = var0;//slot序号 storage[temp6] = memory[temp5:temp5 + 0x20]; arg2 = temp5 + 0x20;//内存位置更新 var0 = temp6 + 0x01;//slot序号+1 var1 = var1; if (var1 <= arg2) { goto label_00D6; } else { goto label_00C4; } } } } else {//一个slot可以装下 var temp7 = arg2;//元素个数 //(memory[var1:var1 + 0x20] & ~0xff)取的是高位,然后最低的一个字节存放 数组长度*2 storage[arg0] = temp7 + temp7 | (memory[var1:var1 + 0x20] & ~0xff); goto label_00D7; } } function func_00E8(var arg0, var arg1) returns (var r0) {//用于在计算哈希后确定的slot位置处,进行写入 if (arg0 <= arg1) {//如果结束的slot序号小于等于开始的序号,这是出口 label_0101: return arg0; } else {//这是一般的入口 label_00F2: var temp0 = arg1;//开始的位置 storage[temp0] = 0x00; arg1 = temp0 + 0x01;//开始的位置+1 if (arg0 <= arg1) { goto label_0101; } else { goto label_00F2; } } } function func_0134(var arg0) returns (var r0) {//(slot0 的数据,256位)用于判断 bytes 的存储方式 var temp0 = arg0; var var0 = temp0 / 0x02;//相当于右移 1 位 var var1 = temp0 & 0x01;//取最低位 //注意,更具规则,如果数据和变量分开存储,那么是2*length+1,那么最低位一定是1。否则,数据一定小于 32 字节 if (!var1) {//如果最低为为0,数据小于32字节 var temp1 = var0 & 0x7f;//继续取出右移后的低七位,它们表示字节长度 var0 = temp1;//字节长度 //如果数组小于32字节,那么元素个数一定小于0x20,那么var1为 0 if (var1 != (var0 < 0x20)) { goto label_0160; } else { goto label_0158; }//异常处理 } else if (var1 != (var0 < 0x20)) {//如果数据超过 31 字节,那么标志位和情况匹配,也是合法 label_0160: return var0;//返回数组的字节长度 } else {//异常处理 label_0158: var var2 = 0x015f; memory[0x00:0x20] = 0x4e487b7100000000000000000000000000000000000000000000000000000000; memory[0x04:0x24] = 0x22;//非法slot编码,panic(0x22) revert(memory[0x00:0x24]); } } }
上面详细分析了动态类型的存储方式,赋值方式。我们可以明白为什么 bytes 和 string 类型,超过 31 字节时,变量所在 slot 存放的时 2*length+1,而小于等于 31 字节时是 2*length,因为需要根据最低位区分这两种情况。超过 31 字节时,变量不会进行 compact,这可能是出于 gas 消耗的考虑,因为需要进行的操作可能非常多。如果开启编译器优化,那么就有可能会根据设定的运行次数,进行计算资源和存储资源的取舍。
下面不妨看看 JEB 逆向后的伪代码,可能抽象程度更高,帮助读者巩固逻辑。注意,它类型推断是不准确的,uint256 只是说明变量占 256 位。其次 *0x40 表示的是内存偏移 0x40 字节后的 32 字节的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 contract DecompiledContract { function start() { *0x40 = 0x80; if(msg.value != 0x0) { revert(0x0, 0x0); } uint256 v0 = *0x40; *0x40 = v0 + 0x40; *(uint256*)v0 = 0x3; *(int256*)(v0 + 0x20) = 0x6162630000000000000000000000000000000000000000000000000000000000; sub_62(*(uint256*)v0, v0 + 0x20, 0x0); codecopy(0x0, 0x174, 0x3F); return(0x0, 0x3F); } function sub_62(uint256 param0, uint256 param1, uint256 param2) private returns (uint256) { uint256 v0; v0 = storage[param0]; uint256 v1 = sub_134(v0); *0x0 = param0; v0 = keccak256(0x0, 0x20); uint256 v2 = v0; v0 = param1; param1 = (v1 + 0x1F) / 0x20 + v2; if(!param2) { storage[param0] = 0x0; } else if(param2 <= 0x1F) { storage[param0] = (param2 * 0x2) | (*(uint256*)v0 & 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00); } else { storage[param0] = param2 * 0x2 + 0x1; if(param2 != 0x0) { uint256 v3 = v0; v0 = param2; param2 = v3; v0 += param2; while(param2 < v0) { storage[v2] = *(uint256*)param2; param2 += 0x20; ++v2; } } } sub_E8(v2, param1); return param0; } function sub_E8(uint256 param0, uint256 param1) private returns (uint256) { while(param0 > param1) { storage[param1] = 0x0; ++param1; } return param0; } function sub_134(uint256 param0) private pure returns (uint256) { uint256 result = param0 / 0x2; if(!(param0 & 0x1)) { result &= 0x7F; } if((param0 & 0x1) != (uint256)(result < 0x20)) { return result; } *0x0 = 0x4E487B7100000000000000000000000000000000000000000000000000000000; *0x4 = 0x22; revert(0x0, 0x24); } }
读者可能发现问题,我们只观察了不超过 31 字节的 bytes 的情况。如果是超过 31 字节的话,bytes 赋值是先从 memory 中 32 字节为单位加载,内存中的值一定是 tight packing 的。
string
string 和 bytes 非常类似,我们只改变上面代码中变量 a 的类型为 string,也来观察它的字节码逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var temp0 = memory[0x40:0x60]; memory[0x40:0x60] = temp0 + 0x40; memory[temp0:temp0 + 0x20] = 0x03; memory[temp0 + 0x20:temp0 + 0x20 + 0x20] = 0x6162630000000000000000000000000000000000000000000000000000000000; var0 = 0x005c; var var1 = 0x00; var var3 = memory[temp0:temp0 + 0x20]; var var2 = temp0 + 0x20; var0 = func_0062(var1, var2, var3); memory[0x00:0x3f] = code[0x0174:0x01b3]; return memory[0x00:0x3f]; } function func_0062(var arg0, var arg1, var arg2) returns (var r0) { var var0 = arg0; var var1 = 0x006e; var var2 = storage[var0]; var1 = func_0134(var2); memory[0x00:0x20] = var0; var0 = keccak256(memory[0x00:0x20]); var temp0 = arg1; arg1 = var0 + (var1 + 0x1f) / 0x20; var1 = temp0; if (!arg2) { storage[arg0] = 0x00; goto label_00D7; } else if (0x1f < arg2) { var temp1 = arg2; storage[arg0] = temp1 + temp1 + 0x01; if (!temp1) { label_00D7: var temp2 = arg1; arg1 = 0x00e4; var0 = var0; arg2 = temp2; arg1 = func_00E8(arg2, var0); return arg0; } else { var temp3 = arg2; var temp4 = var1; arg2 = temp4; var1 = arg2 + temp3; if (var1 <= arg2) { label_00D6: goto label_00D7; } else { label_00C4: var temp5 = arg2; var temp6 = var0; storage[temp6] = memory[temp5:temp5 + 0x20]; arg2 = temp5 + 0x20; var1 = var1; var0 = temp6 + 0x01; if (var1 <= arg2) { goto label_00D6; } else { goto label_00C4; } } } } else { var temp7 = arg2; storage[arg0] = temp7 + temp7 | (memory[var1:var1 + 0x20] & ~0xff); goto label_00D7; } } function func_00E8(var arg0, var arg1) returns (var r0) { if (arg0 <= arg1) { label_0101: return arg0; } else { label_00F2: var temp0 = arg1; storage[temp0] = 0x00; arg1 = temp0 + 0x01; if (arg0 <= arg1) { goto label_0101; } else { goto label_00F2; } } } function func_0134(var arg0) returns (var r0) { var temp0 = arg0; var var0 = temp0 / 0x02; var var1 = temp0 & 0x01; if (!var1) { var temp1 = var0 & 0x7f; var0 = temp1; if (var1 != (var0 < 0x20)) { goto label_0160; } else { goto label_0158; } } else if (var1 != (var0 < 0x20)) { label_0160: return var0; } else { label_0158: var var2 = 0x015f; memory[0x00:0x20] = 0x4e487b7100000000000000000000000000000000000000000000000000000000; memory[0x04:0x24] = 0x22; revert(memory[0x00:0x24]); } } }
几乎是完全类似的。string 和 bytes 只是最后再前端的表现形式不一样。
动态数组
读者应当能够理解下面 solidity doc 中的存储布局介绍。
Assume the storage location of the mapping or array ends up being a slot p after applying the storage layout rules . For dynamic arrays, this slot stores the number of elements in the array (byte arrays and strings are an exception, see below ).
Array data is located starting at keccak256(p) and it is laid out in the same way as statically-sized array data would: One element after the other, potentially sharing storage slots if the elements are not longer than 16 bytes. Dynamic arrays of dynamic arrays apply this rule recursively. The location of element x[i][j], where the type of x is uint24[][], is computed as follows (again, assuming x itself is stored at slot p): The slot is keccak256(keccak256(p) + i) + floor(j / floor(256 / 24)) and the element can be obtained from the slot data v using (v >> ((j % floor(256 / 24)) * 24)) & type(uint24).max.
1 2 3 4 5 6 7 8 9 10 11 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract DynamicVariable { int[] b; constructor(){ b=[int(1),2,3]; } }
逆向后的伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var temp0 = memory[0x40:0x60];//0x80 memory[0x40:0x60] = temp0 + 0x60;//内存拓展0x60字节 memory[temp0:temp0 + 0x20] = 0x01;//0x80-0x9f写入1 var temp1 = temp0 + 0x20; memory[temp1:temp1 + 0x20] = 0x02; memory[temp1 + 0x20:temp1 + 0x20 + 0x20] = 0x03; var0 = 0x3c; var var1 = 0x00;//slot初始位置 var var2 = temp0;//内存初始位置 var var3 = 0x03;//赋值的元素个数 var0 = func_0041(var1, var2, var3); memory[0x00:0x3f] = code[0xb1:0xf0]; return memory[0x00:0x3f]; } function func_0041(var arg0, var arg1, var arg2) returns (var r0) {//(slot起始位置、内存起始位置、需赋值的元素个数) var temp0 = arg0;//slot起始位置 var temp1 = storage[temp0];//取出slot的值 var temp2 = arg2;//需要赋值的元素个数 storage[temp0] = temp2;//这个位置存放数组长度 memory[0x00:0x20] = temp0;//临时存放需要哈希的数 var var0 = keccak256(memory[0x00:0x20]);//计算哈希 var var1 = arg1;//内存起始位置 arg1 = var0 + temp1;//原来slot的值为0,这里用加法,可能是考虑到原来数组已经有值了,然后继续赋值的情况 if (!temp2) {//出口,需要赋值的元素个数为0 label_007A: var temp3 = arg1;//slot开始位置 arg1 = 0x85; var0 = var0;//slot结束位置 arg2 = temp3;//slot开始位置 arg1 = func_0089(arg2, var0); return arg0; } else {//正常入口 var temp4 = arg2;//需要赋值的元素个数 var temp5 = var1;//内存起始位置 arg2 = temp5;//内存起始位置 var1 = arg2 + temp4 * 0x20;//内存结束位置 if (var1 <= arg2) {//循环出口,内存结束位置小于等于内存开始位置 label_0079: goto label_007A;//结束赋值 } else { label_0068: var temp6 = arg2;//内存起始位置 var temp7 = var0;//slot起始位置 storage[temp7] = memory[temp6:temp6 + 0x20];//赋值,注意不会 tight compact arg2 = temp6 + 0x20;//更新内存位置 var0 = temp7 + 0x01;//更新slot起始位置 var1 = var1; if (var1 <= arg2) { goto label_0079; } else { goto label_0068; } } } } function func_0089(var arg0, var arg1) returns (var r0) { if (arg0 <= arg1) {//开始位置小于等于结束位置 label_00A0: return arg0; } else {//异常处理 label_0092: var temp0 = arg1; storage[temp0] = 0x00; arg1 = temp0 + 0x01; if (arg0 <= arg1) { goto label_00A0; } else { goto label_0092; } } } }
多维数组的情况是按照以上规则,递归定义的。例如 uint[][] 可以看作 uint[] 作为元素的动态数组,然后元素 uint[] 的规则和上面的一致,以此类推。
mapping
首先 mapping 的存储布局如下:
For mappings, the slot stays empty, but it is still needed to ensure that even if there are two mappings next to each other, their content ends up at different storage locations.
The value corresponding to a mapping key k is located at keccak256(h(k) . p) where . is concatenation and h is a function that is applied to the key depending on its type:
for value types, h pads the value to 32 bytes in the same way as when storing the value in memory.
for strings and byte arrays, h(k) is just the unpadded data.
If the mapping value is a non-value type, the computed slot marks the start of the data. If the value is of struct type, for example, you have to add an offset corresponding to the struct member to reach the member.
1 2 3 4 5 6 7 8 9 10 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract DynamicVariable { mapping(uint=>uint) c; constructor(){ c[1]=5; } }
下面是逆向后的伪代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } memory[0x00:0x20] = 0x01; memory[0x20:0x40] = 0x00; //key 是1,然后补0成32位。后面是存储变量的slot的位置00 storage[keccak256(memory[0x00:0x40])] = 0x05; memory[0x00:0x3f] = code[0x36:0x75]; return memory[0x00:0x3f]; } }
按照规则,字符串类型会有所不一样,我们假设 Bob 存了 100$,那么用映射表示
1 2 3 4 5 6 7 8 9 10 11 // SPDX-License-Identifier: GPL-3.0 pragma solidity >=0.7.0 <0.9.0; contract DynamicVariable { mapping(string=>uint) c; constructor(){ c["Bob"] = 100; } }
下面是逆向后的伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 contract Contract { function main() { memory[0x40:0x60] = 0x80; var var0 = msg.value; if (var0) { revert(memory[0x00:0x00]); } var0 = 0x64;//Value 100 var var1 = 0x00;//slot位置 var var2 = 0x1e; var var3 = memory[0x40:0x60];//内存开始位置 0x80 var2 = func_0087(var3);//内存结束位置 var temp0 = var2;//内存结束位置 memory[temp0:temp0 + 0x20] = var1;//附加slot位置 var temp1 = memory[0x40:0x60];//内存开始位置 //内存开始位置开始,Bob 连同后面的 0x20 字节的slot位置计算哈希 storage[keccak256(memory[temp1:temp1 + (temp0 + 0x20) - temp1])] = var0; memory[0x00:0x3f] = code[0xa7:0xe6]; return memory[0x00:0x3f]; } function func_0034(var arg0, var arg1) returns (var r0) { return arg1; } function func_003F(var arg0) { memory[arg0:arg0 + 0x20] = 0x426f620000000000000000000000000000000000000000000000000000000000; } function func_0068(var arg0) returns (var r0) { var var0 = 0x00;//slot起始位置 var var1 = 0x73; var var2 = 0x03;//字符长度 var var3 = arg0;//内存开始位置 var1 = func_0034(var2, var3);//内存起始位置 var temp0 = var1;//内存开始位置 arg0 = temp0;//内存开始位置 var1 = 0x7c; var2 = arg0;//内存开始位置 func_003F(var2);//Bob写入内存 return arg0 + 0x03;//内存开始位置+3字节,也就是内存结束位置 } function func_0087(var arg0) returns (var r0) { var var0 = 0x00; var var1 = 0x90; var var2 = arg0;//内存开始位置 return func_0068(var2); } }
虽然看起来比较复杂,但是逻辑较为简单。主要是 string 作为映射的键是不需要填充 0 的,所以需要将 Key 写入内存,并且确定内存中 Key 的结束位置。
小结
Solidity 语言的设计的思路和字节码高度相关。例如动态类型的存储方式的定义,在底层的读写和存储方面,有它设计的道理。
部分默认值实际上并不需要,这说明合约字节码有优化的空间。
不同的类型在字节码操作中都有一定的特征,但是通过字节码推断变量类型却并不是一件容易的事情。