
(十)Fuzzing 基础
这主要是[1]的阅读总结
Fuzzing 是什么
在众多软件测试技术中,Fuzzing 因其概念的简单性、易于部署以及在发现实际软件漏洞方面的有效性而受到广泛青睐。简而言之,Fuzzing 是使用异常或非预期的输入(称为“fuzz 输入”)来运行待测试的程序(Program Under Test, PUT)的过程。这种 fuzz 输入是 PUT 可能没有预料到的,也就是说,它可能会使 PUT 处理不当,从而触发开发者未预期的行为。
定义 1 (Fuzzing):Fuzzing 是指使用从所谓的“fuzz 输入空间”中抽取的输入来执行 PUT 的过程,这个输入空间超出了 PUT 的预期输入范围。
定义 2 (Fuzz Testing):Fuzz 测试是利用 fuzzing 来检查 PUT 是否违反了某些特定的正确性策略。
定义 3 (Fuzzer):Fuzzer 是进行 fuzz 测试的工具,专门用于测试 PUT。
定义 4 (Fuzz Campaign):Fuzz campaign 是在特定的正确性策略下,对 PUT 执行 fuzzer 的特定过程。
定义 5 (Bug Oracle):Bug oracle 是一个程序,有时作为 fuzzer 的一部分,用于判断 PUT 的特定执行是否违反了某个特定的正确性策略。
通过这些定义,Fuzzing 作为一种测试方法提供了一种系统化和自动化的方式来探测软件中的潜在漏洞,使软件开发者能够更有效地确保软件的稳定性和安全性。
通用 Fuzz 测试算法
在讨论 fuzz 配置时,需要注意的是,配置中的值类型取决于所使用的 fuzz 算法。例如,向待测试程序(PUT)发送随机字节流的简单 fuzz 算法具有一个基础的配置空间。而另一方面,更复杂的 fuzzers 则包含接受一系列配置并随时间进行调整的算法,这可能包括配置的添加和删除。
种子是传递给 PUT 的一个通常结构良好的输入,它被用于通过修改生成测试用例。Fuzzers 通常维护一个称为“种子池”的种子集合,而且某些 fuzzers 会随着 fuzz campaign 的进行而更新这个池。

算法 1 接受一组 fuzz 配置和一个时间限制作为输入,并输出一组发现的 bug 。该算法的第一部分是PREPROCESS函数,它在 fuzz campaign 开始时执行。第二部分是循环中的五个函数系列:SCHEDULE、INPUTGEN、INPUTEVAL、CONFUPDATE和CONTINUE。
每次循环的执行被称为fuzz iteration,而每次INPUTEVAL在一个测试用例上执行 PUT 的动作被称为fuzz run。
-
用户为
PREPROCESS提供一组 fuzz 配置作为输入,它返回可能修改的 fuzz 配置集合。根据所使用的 fuzz 算法,PREPROCESS可能执行各种操作,例如向 PUT 插入监测代码或测量种子文件的执行速度。 -
SCHEDULE接受当前的 fuzz 配置集、当前已经过去的时间和一个时间限制作为输入,并选择一个 fuzz 配置用于当前的 fuzz iteration。 -
INPUTGEN接收一个 fuzz 配置作为输入,并返回一组具体的测试用例作为输出。在生成测试用例时,INPUTGEN使用中的特定参数。某些 fuzzer 使用中的种子生成测试用例,而其他 fuzzer 可能使用模型或语法作为参数。 -
INPUTEVAL接收一个 fuzz 配置、一组测试用例和一个 bug oracle 作为输入。它在上执行 PUT,并使用检查执行是否违反了正确性策略。
这些定义和过程展示了 fuzzing 作为软件测试中的一个复杂且灵活的方法,它通过多种方式生成和评估测试用例,以检测和识别软件中的潜在错误和漏洞。
Fuzzers 的分类
Fuzzers 可以根据在每次 fuzz 运行中所采用的语义粒度分为三类:黑盒、灰盒和白盒 fuzzers。
黑盒 fuzzer是一种不涉及检查待测试程序(PUT)内部逻辑的技术。这种 fuzzer 仅仅关注 PUT 的输入和输出。在软件测试领域,黑盒测试也被称为 IO(输入/输出)驱动或数据驱动测试。然而,有些研究工作使用适应性策略来为黑盒 fuzzers 生成更有效的测试用例。
与黑盒 fuzzers 相对的是白盒 fuzzer,它通过分析 PUT 的内部结构和执行过程中收集的信息来生成测试用例。动态符号执行(Dynamic Symbolic Execution, DSE)是白盒 fuzzing 的一个例子,因为它通过具体的运行时状态替换一些符号值来执行测试。
灰盒 fuzzer则采取了一种中间态度,它获取了 PUT 的部分内部信息和/或其执行过程中的信息。与白盒 fuzzers 不同,灰盒 fuzzers 不会深入推理 PUT 的全部语义;相反,它们可能会对 PUT 执行一些轻量级的静态分析,和/或收集关于其执行的动态信息,例如代码覆盖率。这种方法通常依赖于近似和不完全的信息,以此来提高速度,并能够测试更多的输入。
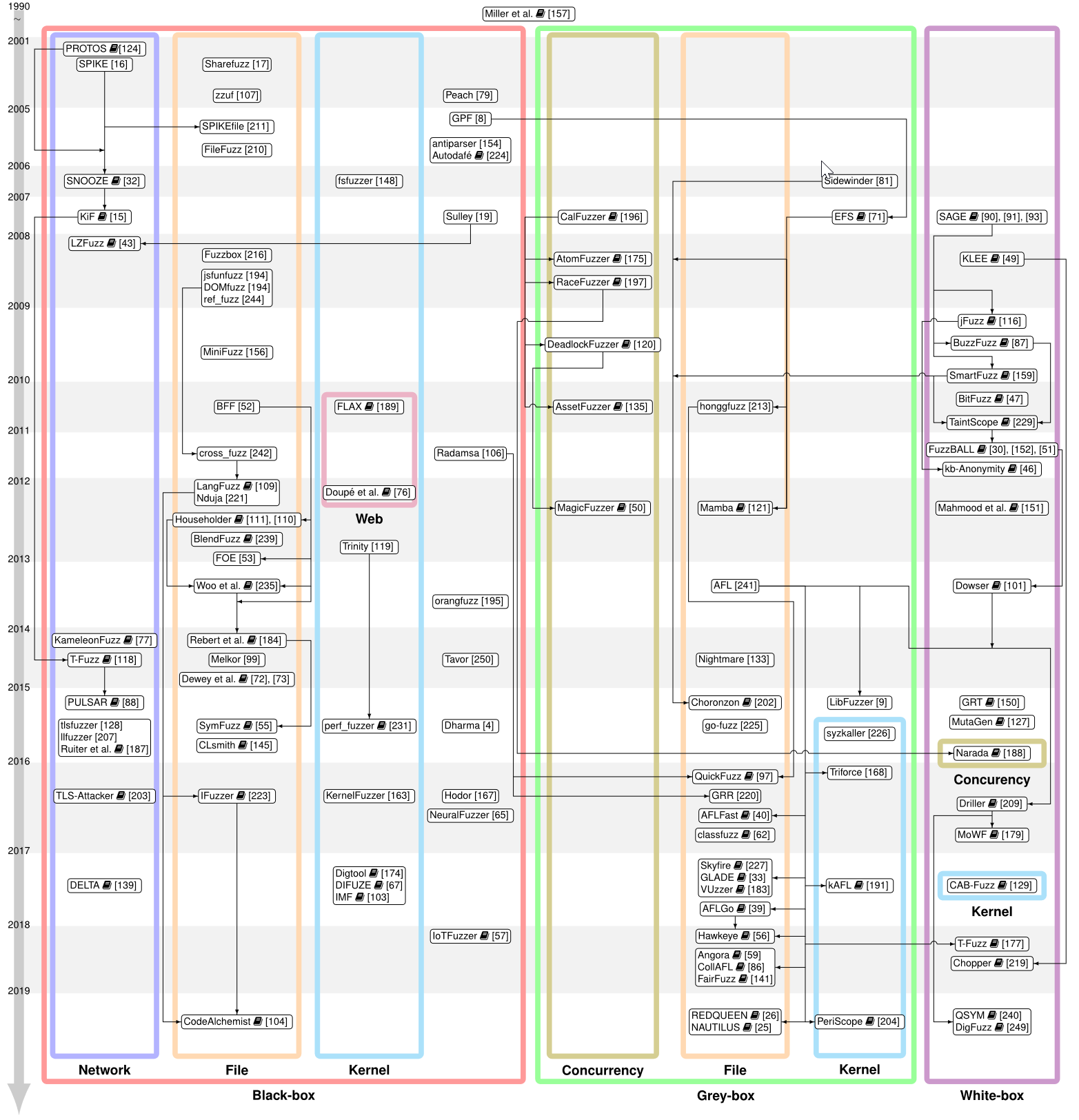
从 X 到 Y 的实线箭头表示 Y 引用、参考或以其他方式使用来自 X 的技术。
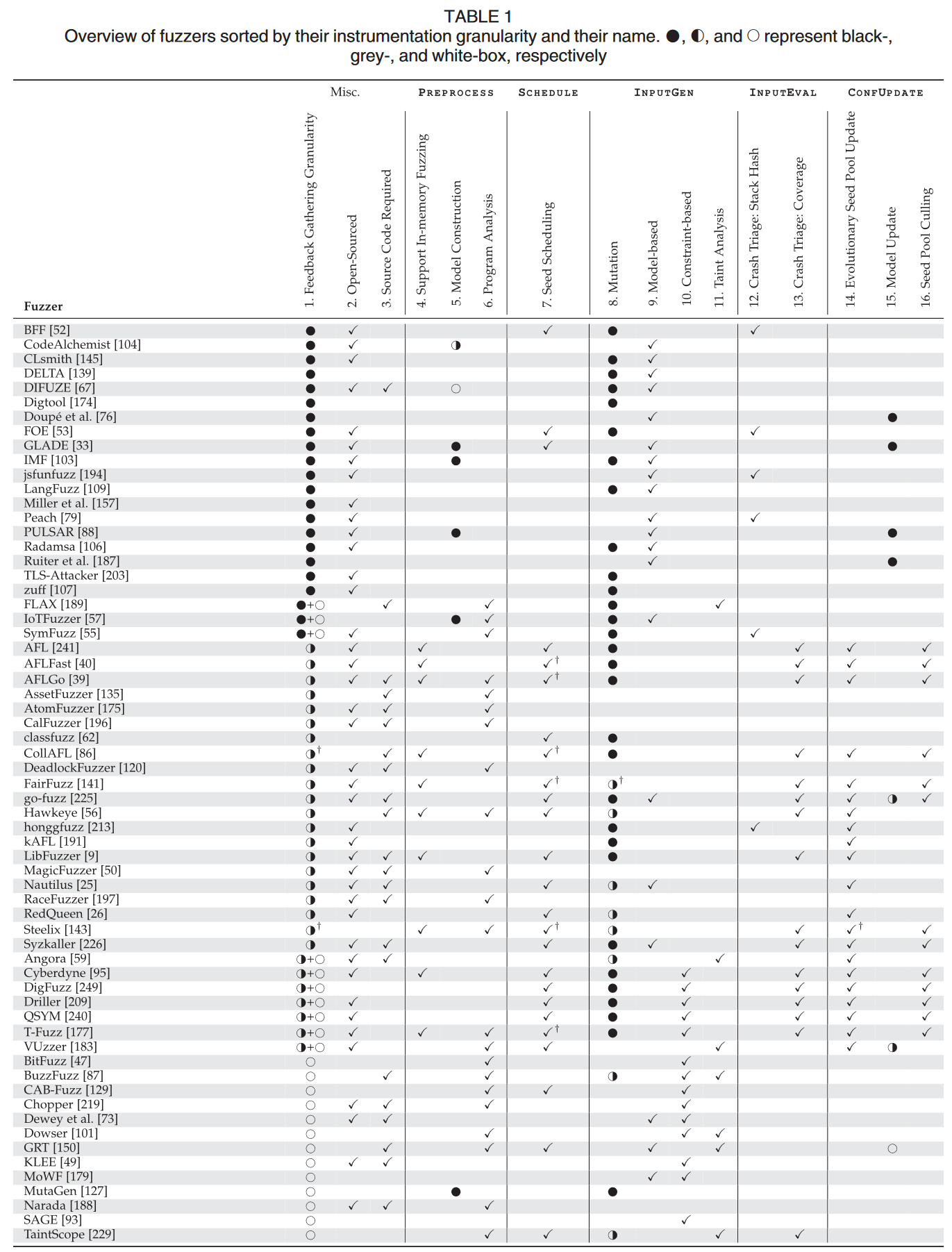
- Fuzzer 类型(第 1 列):标识 fuzzer 是黑盒(⬤)、白盒(◑)还是灰盒(○)。如果 fuzzer 在不同阶段采用不同类型的反馈机制,会显示两个圆圈,反映其混合方法。
- 源代码公开性(第 2 列):显示 fuzzer 的源代码是否公开,这有助于用户了解、修改和定制 fuzzer。
- 源代码需求(第 3 列):指示 fuzzer 是否需要访问 PUT 的源代码来进行测试,这影响了 fuzzer 的适用性和灵活性。
- 内存中 Fuzzing(第 4 列):表明 fuzzer 是否支持内存中 fuzzing,这种方式可以在不实际运行 PUT 的情况下进行测试,有助于提高效率。
- 模型推断(第 5 列):关于 fuzzer 是否能够推断出 PUT 的模型,这有助于生成更精确的测试用例。
- PREPROCESS 中的静态分析(第 6 列):显示 fuzzer 在
PREPROCESS阶段是否执行静态或动态分析,这影响了测试用例的生成和优化。 - 多种子处理(第 7 列):表示 fuzzer 是否支持处理多个种子并进行调度,这有助于提高测试用例的多样性。
- 输入变异(第 8 列):指定 fuzzer 是否执行输入变异来生成测试用例。◑ 表示 fuzzer 根据执行反馈来指导输入变异。
- 基于模型的测试用例生成(第 9 列):关于 fuzzer 是否基于模型生成测试用例,这可以提高测试的准确性和效率。
- 符号分析(第 10 列):显示 fuzzer 是否使用符号分析来生成测试用例,这有助于发现更深层次的漏洞。
- 污点分析(第 11 列):标识利用污点分析来指导测试用例生成的 fuzzer,这有助于识别潜在的安全漏洞。
- 崩溃分类(第 12 和 13 列):显示 fuzzer 是否使用堆栈哈希或代码覆盖率来执行崩溃分类,这对于识别和区分不同的崩溃类型很重要。
- 种子池进化(第 14 列):表示 fuzzer 在
CONFUPDATE期间是否进化种子池,例如添加新种子,这有助于提高测试的广度和深度。 - 在线学习输入模型(第 15 列):关于 fuzzer 是否在线学习输入模型,这有助于动态调整和优化测试策略。
- 移除种子(第 16 列):显示哪些 fuzzer 会从种子池中移除种子,这有助于优化种子池,提高测试效率。
另外,您可以在 fuzzing-survey 上找到知识图谱。
PREPROCESS
在 fuzzing 的预处理阶段,某些 fuzzers 会通过修改初始 fuzz 配置集来准备主循环,作为首要步骤。预处理的目的通常是为了对待测试程序(PUT)进行插桩、去除可能冗余的配置、修剪种子,以及生成驱动应用程序。
插桩
不同于黑盒 fuzzers,灰盒和白盒 fuzzers 可以对 PUT 进行插桩,以便在 INPUTEVAL 阶段执行 fuzz 运行时收集执行反馈,或者在运行时 fuzz 内存中的内容。
程序插桩可以是静态的或动态的。静态插桩通常在 PUT 运行之前进行,比如在编译时对源代码或中间代码进行修改。由于静态插桩在运行时之前完成,通常比动态插桩带来的开销要小。动态插桩则在 PUT 运行时进行,能够轻松地对动态链接的库进行插桩。
插桩的具体实现可能包括:
- 执行反馈:例如,LibFuzzer 和 AFL 通过对每个分支指令进行插桩来计算分支覆盖率。
- 线程调度:插桩还可以控制线程的调度,触发非确定性的程序行为,例如竞态条件错误。
- 内存中模糊:通过在复杂的初始化之后对 PUT 进行快照,可以避免每次迭代都重新生成一个进程。新的测试用例可以通过恢复内存快照后直接写入内存来模糊。
种子选择与种子修剪
Fuzzers 接收一组控制 fuzzing 算法行为的配置。但某些参数可能有很大或甚至无限的域。种子选择问题涉及如何减少初始种子池的大小。
一个常见的方法,称为minset,找到一个最小的种子集,该种子集最大化了覆盖度指标,如节点覆盖度。例如,假设当前的配置集由两个种子和组成,它们覆盖 PUT 的以下地址:。如果我们有第三个种子,执行速度大致与和相同,那么可以认为使用进行模糊测试比使用和更有意义,因为执行的时间成本更低,但是测试了相同的代码集,有相同的覆盖度。
Fuzzers 在实践中使用了各种不同的覆盖度指标。例如,AFL 的 minset 是基于分支覆盖度的,每个分支上有一个对数计数器。这背后的理念是只有当它们的数量级不同时,才认为分支计数是不同的。Honggfuzz 基于执行的指令数、执行的分支数和 unique 的基本块 (basic block, 可以简单认为连续顺序执行的一段指令) 来计算覆盖度。这个指标允许 fuzzer 将较为费时的种子配置添加到 minset 中,这有助于发现拒绝服务漏洞或性能问题。
此外,种子修剪减少种子池的大小。例如,AFL 使用代码覆盖度插桩来迭代地移除部分种子,只要修改后的种子能达到相同的覆盖度。通过这些技术,fuzzers 能够更有效地执行测试,提高漏洞发现的几率,同时减少不必要的计算和资源消耗。
SCHEDULING
回顾之前的通用算法,调度的过程涉及选择下一个 fuzz 迭代的 fuzz 配置,通过分析当前可用信息来实现最优结果,例如最大化覆盖率。在更先进的 fuzzers 中,如 BFF 和 AFLFast,它们的成功在很大程度上归功于它们创新的调度算法。
在黑盒设置中,**FCS(Fuzz Configuration Scheduling)**算法能够使用的唯一信息是关于一个配置的 fuzz 结果——目前使用该配置发现的崩溃和漏洞数量,以及到目前为止在该配置上花费的时间。
在灰盒设置中,FCS 算法可以访问关于每个 fuzz 配置的更丰富信息集,例如,在 fuzz 一个配置时所达到的代码覆盖率。AFL 是这一类别的先驱,它基于进化算法(EA)。直观地说,EA 维护一个 fuzz 配置的种群,每个配置都有一定的“适应度”值。EA 选择适合的配置,并对其应用基因转换,如突变和重组,产生后代,这些后代可能在未来成为新的 fuzz 配置。这种方法的假设是,这些生成的配置更有可能适应目标环境。
如果你对灰盒调度算法的细节感兴趣,可以关注 AFL 到 AFLFast,再到 AFLGo 的发展,这一系列的进化展示了调度算法的进步。此外,还有一些后续的 fuzzers 利用静态分析来进一步提高效率和效果。这些工具和方法的发展不断推动着软件测试和安全研究的前沿,使 fuzzing 成为一个日益重要和有效的工具。
INPUT GENERATION
在 fuzzer 的设计中,用于input generation的技术是其中最关键的部分。基本上,fuzzers 可以分为两种类型:生成型和变异型。
- 生成型 fuzzer根据描述待测试程序(PUT)期望输入的模型来生成测试用例。这类 fuzzers 可以由用户通过预定义模型进行配置,提供 API 以创建自定义输入模型,或接收用户提供的协议规范和基于语法的输入。
- 变异型 fuzzer通常被认为没有明确的模型,因为种子仅是示例输入,并没有完全描述 PUT 的预期输入范围。
Generation-Based Fuzzers
- 预定义模型:用户可以配置预定义的模型。这类 fuzzer 允许用户创建自己的输入模型或接收用户提供的协议规范、基于语法的输入。
- 推导模型:不依赖于预定义或用户提供的模型,而是推导出模型。这种推导可能在
PREPROCESS阶段进行,包括通过数据驱动方法推导控制流图,或通过分析 API 记录来推导输入。例如,PULSAR 可以根据一套捕获的网络数据包自动推导出网络协议模型,然后使用学到的网络协议对程序进行 fuzz。
Mutation-Based Fuzzers
变异型 fuzzers 是一种在软件测试中广泛使用的工具,它们通过修改现有的输入数据(种子)来生成新的测试用例。这种方法特别适合于测试复杂软件系统,但是生成特定路径条件的测试用例的难度较大。
经典的随机生成测试用例的方法,在需要满足特定路径的条件时,效率不高。考虑一个简单的 C 语句:if (input == 42)。如果输入是 32 位整数,随机猜测正确的输入值的概率是。变异型 fuzzers 正是在这样的背景下产生的,其目标是从现有种子中筛选出最有可能触发新路径或行为的种子。
Bit-flipping是许多 fuzzer 常用的一种技巧。为了随机地变异种子,一些 fuzzer 采用一个称为 mutation ratio 的用户参数,这决定了在INPUTGEN的单次执行中要翻转(0 与 1 互相替换)的位的数量。
Arithmetic Mutation这种方法将种子中的特定部分视为整数,并对其执行简单的算术操作。例如,AFL 可能会随机选择种子中的一个 4 字节值,并用一个随机生成的小整数替换它。
还有几种block-based mutation策略,其中 block 是种子的连续字节:
- 在种子的随机位置插入随机生成的块。
- 从种子中删除随机选择的块。
- 用随机值替换随机选择的块。
- 调整种子的大小,例如通过添加随机块。
- 从一个种子中取一个随机块插入到另一个种子的随机位置。
预定义值替换:在某些情况下,使用预定义的值(如格式字符%s和%x)替换输入中的某些部分,特别是在针对格式字符串漏洞的测试中。
White-box Fuzzer 的程序分析
对于白盒 fuzzers,它们通过执行复杂的静态或动态分析来进行深入的变异,从而能够更准确地识别潜在的漏洞和错误。例如,Dowser 这样的工具在编译阶段执行静态分析,利用启发式方法寻找可能包含错误的代码区域,特别是循环结构。
Dynamic Symbolic Execution
从高层次来看,动态符号执行使用符号值作为输入来运行程序,而不是具体的值。当执行待测试程序(PUT)时,它会构建符号表达式。每当遇到条件分支指令时,动态符号执行会分叉两个符号执行环境:一个代表真分支,另一个代表假分支。对于每个路径,动态符号执行会构建一个路径公式,如果存在满足该路径的具体输入,则该路径公式是可满足的。人们可以通过查询 SMT(Satisfiability Modulo Theories)求解器获得路径公式的解,从而生成具体的输入。
然而,与灰盒或黑盒方法相比,动态符号执行的速度相对较慢。为了解决这个问题,一个常见的策略是结合灰盒 fuzzing 来估计执行每个路径的概率,或者是用户指定 PUT 的某些部分来专门进行动态符号执行。
Guided Fuzzing
导向 fuzzing 主要分为两个阶段:
- 对 PUT 进行深入的程序分析以获取有用信息。
- 根据前面的分析生成测试用例。
例如,TaintScope 使用精细的污点分析来找出“热点字节”,即那些流入关键系统或 API 调用的输入字节。Angora 则改进了这种“热点字节”的方法,使用污点分析将每个路径约束与相应的字节相关联。接着,Angora 采用梯度下降算法的启发式搜索来引导其变异,以解决这些约束。
通过这些高级的分析和变异技术,白盒 fuzzers 能够更有效地探测到程序中的复杂错误和漏洞,使得 fuzzing 测试更为深入和全面。这些方法的应用不仅提高了 fuzzing 的效果,也为软件测试和安全分析提供了更多的可能性。
INPUT EVALUATION
在生成输入之后,fuzzer 会在此输入上执行 PUT 并决定如何处理执行结果。此过程称为input evaluation。
关键目的是使用 bug oracle 检测 bug,它是一种安全策略。例如,由于指针覆盖导致的内存漏洞在被解引用时可能会抛出段错误。此外,研究者提出了多种方法来高效地检测不安全或不期望的程序行为。
- Memory and Type Safety:追踪有效内存地址和不兼容的类型转换;检测非法的控制流修改。
- Input Validation:例如 XSS 和 SQL 注入漏洞。
- Semantic Difference:语义错误通常通过differential testing方法发现,该方法比较相似(但不完全相同)的程序的行为,比如对同一协议的不同实现的库,进行测试。
fuzzer 在评估阶段应该对程序 bug 的结果进行分类和分析。分析和报告违反策略的测试用例的过程称为triage。
首先,deduplication是一种修剪输出集的过程,其中删除了那些触发与其他测试用例相同错误的输出。它避免了在硬盘上存储重复的结果,也更加概括性地呈现运行结果。
目前在实践中使用的三种主要去重方法是:stack backtrace hashing、coverage-based deduplication 和Semantics-aware Deduplication。
-
Stack backtrace hashing:在此方法中,一个自动化工具会在崩溃时记录 stack backtrace,并基于该 backtrace 的内容分配一个 stack hash。例如,如果程序在执行 function
foo的某行代码时崩溃,并且调用堆栈为,那么对于特定栈长度的 stack backtrace hashing 的类别,其他调用堆栈如果以崩溃,那么就算做一类。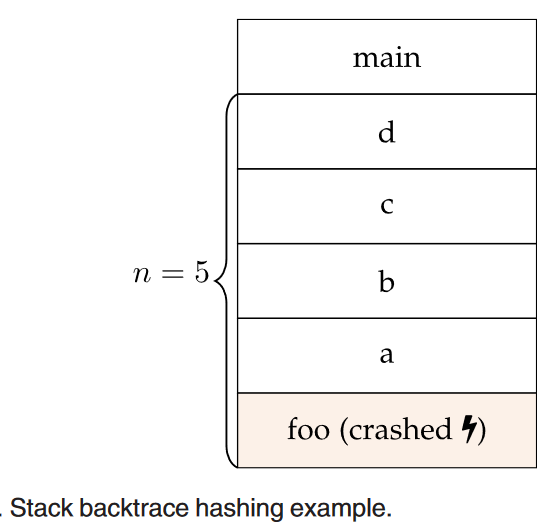
-
Coverage-based Deduplication:AFL 根据是否覆盖了新的程序路径来确定崩溃是否独特。
-
Semantics-aware Deduplication:例如,RETracer 通过反向数据流分析来分类崩溃,通过分析崩溃转储来确定哪个指针引起了崩溃,并递归地跟踪哪个指令赋予了错误的值。
Prioritization,也称为 fuzzer 中的taming problem,是根据测试用例触发的漏洞的严重性和独特性对其进行排序或分类的过程。而exploitability则用于非正式地评估开发出实际攻击工具的可能性。
triage的另一个重要部分是test case minimization。它生成一个比原来更小、更简单但仍然导致违规的测试用例。这一步骤对于精确定位漏洞和简化复杂的测试用例至关重要。
input evaluation阶段在 fuzzing 过程中扮演着关键角色,不仅涉及 bug 的检测和分类,还包括对测试用例进行有效的优化和简化,以提高后续分析的效率和精确性。
CONFIGURATION UPDATING
黑盒 fuzzer 的CONFUPDATE函数的行为,与灰盒或白盒 fuzzer 非常不同。这个函数允许 fuzzer 根据在当前 fuzzing 运行中收集到的配置和执行信息来修改配置集合。这种动态调整配置的能力是灰盒和白盒 fuzzing 策略的核心部分,使得 fuzzing 过程可以根据实时反馈进行自适应调整。
在基于进化算法(EA)的 fuzzers 中,CONFUPDATE函数特别重要。这些 fuzzers 在新个体被发现的过程中维护一个所谓的“有前景的”种子池,使种子池随着 fuzz 活动的进行而不断进化。大多数基于 EA 的 fuzzers 使用节点或分支覆盖作为适应性函数,来衡量种子的有效性。
因此,一个重要的研究领域是精化适应性函数,使其能够检测到更微妙和更细粒度的改进指标。例如,AFL 优化其适应性函数定义,通过记录分支被执行的次数来评估每个种子的有效性。这种方法允许 fuzzer 优先考虑那些可能探索到程序新路径的种子,从而更有效地覆盖更广泛的代码区域。
此外,一些 fuzzers 还会使用其他指标,如代码路径的独特性、执行时间、内存使用等,来进一步细化种子的选择和变异策略。通过不断调整和优化这些参数,CONFUPDATE函数使 fuzzer 能够更智能地响应测试过程中的发现,从而提高整体 fuzzing 过程的效率和有效性。
Reference
- Manès, V. J., Han, H., Han, C., Cha, S. K., Egele, M., Schwartz, E. J., & Woo, M. (2019). The art, science, and engineering of fuzzing: A survey. IEEE Transactions on Software Engineering, 47(11), 2312-2331.
- H. Gascon, C. Wressnegger, F. Yamaguchi, D. Arp, and K. Rieck, “PULSAR: Stateful black-box fuzzing of proprietary network protocols,” in Proc. Int. Conf. Security Privacy Commun. Syst.,2015, pp. 330–347.
- I. Haller, A. Slowinska, M. Neugschwandtner, and H. Bos, “Dowsing for overflows: A guided fuzzer to find buffer boundary violations,” in Proc. USENIX Security Symp.,2013, pp. 49–64
- T. Wang, T. Wei, G. Gu, and W. Zou, “TaintScope: A checksumaware directed fuzzing tool for automatic software vulnerability detection,” in Proc. IEEE Symp. Security Privacy, 2010, pp. 497–512.
- P. Chen and H. Chen, “Angora: Efficient fuzzing by principled search,” in Proc. IEEE Symp. Security Privacy, 2018, pp. 855–869.
- W. Cui, M. Peinado, S. K. Cha, Y. Fratantonio, and V. P. Kemerlis, “RETracer: Triaging crashes by reverse execution from partial memory dumps,” in Proc. Int. Conf. Softw. Eng., 2016, pp. 820–831.




